O2 DSL IPv6 : Immer wieder TCP Verbindungsreset bei Zugriff auf Cloudflare IPv6 Adressen.
Seit einigen Tagen, eventuell Wochen, habe ich immer wieder Probleme, dass Webseiten beim Laden abbrechen. Nach einiger Analyse, scheint es so zu sein, dass das Seiten betrifft, die über cloudflare IPv6 angebunden sind, und sehr “nahe” am O2 Netz dran sind (ping ist 20 ms). Z.B. diese Seite hier, über wget geladen, hat gerade in mehr als 30% der Fälle einen Verbindungsabbruch:
wget --progress=dot -O/dev/null -6 https://understandingwar.org --2023-07-11 13:41:13-- https://understandingwar.org/ Resolving understandingwar.org (understandingwar.org)... 2606:4700:10::ac43:1963, 2606:4700:10::6816:4e94, 2606:4700:10::6816:4f94 Connecting to understandingwar.org (understandingwar.org)|2606:4700:10::ac43:1963|:443... connected. GnuTLS: Error in the pull function. Unable to establish SSL connection.
Wenn ich das mit tcpdump aufzeichne, dann sehe ich, dass der Webserver, nach dem TLS “Client Hello” sofort mit TCP Reset antwortet. Da der Ping sehr kurz ist, sieht das für mich so aus, als wenn da irgendwelche caching proxies innerhalb des O2 Netzes die Verbindung abwürgen. Irgendein falsch konfigurierter DoS Schutz oder sowas.
Die gesamte Verbindung unfasst nur 5 IP Pakete, die laut tcpdump so hier aussehen (habe meine eigene IPv6 Adresse zum Schutz der Privatsphäre teilw. maskiert):
Das ganze läuft bei mir unter Linux direkt mit einem DSL-Modem, da ist auf meiner Seite kein Router etc. dazwischen, dem man die Schuld in die Schuhe schieben kann.
Die Route zu dem Webserver ist laut traceroute folgende:
traceroute to 2606:4700:10::ac43:1963 (2606:4700:10::ac43:1963), 30 hops max, 80 byte packets 1 2a02:3001::240 (2a02:3001::240) 12.686 ms 12.600 ms 12.638 ms 2 * 2a02:3001::2df (2a02:3001::2df) 10.637 ms * 3 * * * 4 * * * 5 2a02:3001::280 (2a02:3001::280) 21.089 ms 2a02:3001::22d (2a02:3001::22d) 21.389 ms 2a02:3001::3f (2a02:3001::3f) 20.939 ms 6 * 2a02:3040:0:10::39 (2a02:3040:0:10::39) 26.972 ms * 7 2400:cb00:470:3:: (2400:cb00:470:3::) 33.382 ms 2400:cb00:100:1024::ac44:6d1c (2400:cb00:100:1024::ac44:6d1c) 23.924 ms 2400:cb00:100:1024::ac44:6d12 (2400:cb00:100:1024::ac44:6d12) 26.544 ms
Seite 2 / 2
xkcd.com hat bei mir auch dieselben Probleme wie die anderen Cloudflare Seiten hier im Thread. Mittlerweile habe ich IPv6 im Browser deaktiviert, ist mit dem Packetloss nicht wirklich benutzbar. In Firefox geht das über about:config → network.dns.disableIPv6.
Ich bin sehr froh, dass ich diesen Thread gefunden habe, weil ich bei mir ebenfalls Probleme sehe und es inzwischen immer gravierendere Auswirkungen hat. Ja, ich bin auch in Berlin mit VDSL + Fritzbox.
Ich habe die Probleme v.a. mit fastly bemerkt. Mein Anwendungsfall ist aber nicht der Browser, sondern v.a. github und pypi. Meistens funktioniert die Verbindung auch, aber gefühlt in 10-20% der Fälle die Verbindung ab. Vermutlich habe ich das Problem auch im Browser schon gesehen, aber ignoriert oder auf mein Handy geschoben (Symptome: lange Wartezeiten bis zum Laden einzelner Seiten, z.T. werden Grafiken oder CSS nicht geladen).
Ich kann ggf. gerne mehr traces usw. zur Verfügung stellen.
Wie geht es denn den anderen Berlinern hier im Thread beim Zugriff auf xkcd.com?
Ich habe bei mir gerade einen Test gemacht mit
curl -s -6 https://xkcd.com > /dev/null
und anschließend den returncode unter Linux ausgewertet.
Bei 100 Versuchen gab es 46 Fehlschläge, sollte also ziemlich gut zu reproduzieren sein.
Update: Spaßeshalber noch mal mit 1000 Versuchen durchlaufen lassen, Fehlerquote 47,8%.
ist mit dem Packetloss nicht wirklich benutzbar
vorsicht, das ist kein Packetloss, sondern es wird “Serverseitig” (bzw. irgendwo auf dem Netzwerkpfad) ein Reset gesendet. Das ist etwas anderes als Packetverlust.
Hoffentlich gibt es bald eine Rückmeldung dazu, ein Moderator hatte ja vor etwa einem Monat erneut intern nachgefragt.
Hier scheint das Problem auch vorhanden zu sein, ebenfalls nähe Berlin.
Jedoch fehlt dort Traceroute und IPv6 Adressen, sowie Infos wo genau das Spiel hinspricht. Jedoch führte das deaktivieren von IPv6 dazu, dass keine Verbindungsprobleme mehr auffielen.
Vermutlich ist der traceroute gar nicht so interessant, aber mal der Vollständigkeit halber (einige Spalten hinten wegen besserer Lesbarkeit entfernt).
Danke dir, @derp_96883 :-)
Damit lässt sich doch schon mal was anfangen und einen ersten Verdacht habe ich da auch schon.
Auch, wenn wir selbst da nicht eingreifen können, kennen wir da doch den einen und anderen Menschen, der sich das gerne mal anschaut. Mit den Traces sollte sich da bestimmt etwas heraus bekommen lassen.
Vermute gerade, dass es sich um das Problem handelt, was hier beschrieben wird: TCP Reset wegen Anycast Shift. Also ein Problem mit Anycast Routing nah am oder im O2 Netz.
Deswegen betrifft das Cloudflare, Neocities und Fastly: das sind alles potentielle Anycast IPv6 Adressen. Da sitzt dann also irgendwo im Pfad von Berlin nach Frankfurt ein ECMP Router, der das “Client Hello” an den falschen Anycast-host routed. Und der antwortet dann halt mit RST, weil der von nichts weiß, weil das initiale SYN bei einem anderen Host gelandet war?
Können wir das Problem denn aktuell noch bei Cloudflare nachvollziehen? Die initial genannten Domains funktionieren bei mir problemlos.
Was allerdings nicht funktioniert sind xkcd.com, gnome.org, pypi (download) und (Teile von) github. Diese Domains laufen alle über fastly.
@o2_Lars Vielleicht könnt ihr da noch mal reinschauen?
Können wir das Problem denn aktuell noch bei Cloudflare nachvollziehen? Die initial genannten Domains funktionieren bei mir problemlos.
Was allerdings nicht funktioniert sind xkcd.com, gnome.org, pypi (download) und (Teile von) github. Diese Domains laufen alle über fastly.
@o2_Lars Vielleicht könnt ihr da noch mal reinschauen?
Also ich bekomme stochastische IPv6 TCP Resets z.B. bei nextspaceflight.com. Die IPv6 gehört zu Google. Die entsprechende IPv6 Adresse wird im DNS auch reverse aufgelöst zu “any-in-2001-4860-4802-32--15.1e100.net.”. Die heißt sogar “any-”, wie in Anycast.
Traceroute liefert je nach Aufruf verschiedene Pfade. Das wäre ein weiteres Indiz für Anycast Shift (je nach Routing-Pfad kommt er womöglich bei einem anderen Anycast-Host raus).
$ wget -6 -O/dev/null https://nextspaceflight.com --2024-10-10 08:20:57-- https://nextspaceflight.com/ Resolving nextspaceflight.com (nextspaceflight.com)... 2001:4860:4802:32::15, 2001:4860:4802:34::15, 2001:4860:4802:36::15, ... Connecting to nextspaceflight.com (nextspaceflight.com)|2001:4860:4802:32::15|:443... connected. GnuTLS: Error in the pull function. Unable to establish SSL connection.
$ traceroute 2001:4860:4802:32::15 traceroute to 2001:4860:4802:32::15 (2001:4860:4802:32::15), 30 hops max, 80 byte packets 1 2a02:3001::240 (2a02:3001::240) 55.037 ms 54.948 ms 55.031 ms 2 2a02:3001::2df (2a02:3001::2df) 12.179 ms * 12.059 ms 3 loopback0.0003.corx.01.ber.de.net.telefonica.de (::ffff:62.52.192.168) 21.897 ms 20.818 ms * 4 * * * 5 2a02:3001::1b7 (2a02:3001::1b7) 16.491 ms 2a02:3001::22d (2a02:3001::22d) 22.885 ms 2a02:3001::280 (2a02:3001::280) 22.839 ms 6 * * * 7 2a00:1450:8116::1 (2a00:1450:8116::1) 22.538 ms 2a00:1450:809c::1 (2a00:1450:809c::1) 22.525 ms 2001:4860:1:1::56a (2001:4860:1:1::56a) 22.869 ms 8 any-in-2001-4860-4802-32--15.1e100.net (2001:4860:4802:32::15) 21.545 ms 21.528 ms 2a00:1450:8063::1 (2a00:1450:8063::1) 22.277 ms
$ traceroute 2001:4860:4802:32::15 traceroute to 2001:4860:4802:32::15 (2001:4860:4802:32::15), 30 hops max, 80 byte packets 1 2a02:3001::240 (2a02:3001::240) 30.048 ms 30.113 ms 30.051 ms 2 * 2a02:3001::2df (2a02:3001::2df) 12.399 ms 12.155 ms 3 loopback0.0003.corx.01.ber.de.net.telefonica.de (::ffff:62.52.192.168) 21.379 ms * * 4 * loopback0.0003.corx.01.ham.de.net.telefonica.de (::ffff:62.52.192.179) 20.940 ms * 5 2a02:3001::280 (2a02:3001::280) 22.900 ms 2a02:3001::22d (2a02:3001::22d) 22.847 ms 2a02:3001::1b7 (2a02:3001::1b7) 15.948 ms 6 * 2001:4860:1:1::ff1 (2001:4860:1:1::ff1) 19.875 ms * 7 2001:4860:0:1::8123 (2001:4860:0:1::8123) 17.387 ms 2001:4860:1:1::ff0 (2001:4860:1:1::ff0) 14.866 ms * 8 2001:4860:0:1::1c5b (2001:4860:0:1::1c5b) 18.095 ms 2001:4860:0:1::21a5 (2001:4860:0:1::21a5) 20.468 ms 2001:4860:0:1::878b (2001:4860:0:1::878b) 15.824 ms 9 any-in-2001-4860-4802-32--15.1e100.net (2001:4860:4802:32::15) 20.961 ms 20.848 ms 2001:4860:0:1::5321 (2001:4860:0:1::5321) 14.760 ms
$ traceroute 2001:4860:4802:32::15 traceroute to 2001:4860:4802:32::15 (2001:4860:4802:32::15), 30 hops max, 80 byte packets 1 2a02:3001::240 (2a02:3001::240) 30.570 ms 30.514 ms 30.451 ms 2 2a02:3001::2df (2a02:3001::2df) 12.065 ms 13.144 ms * 3 loopback0.0003.corx.01.ber.de.net.telefonica.de (::ffff:62.52.192.168) 21.493 ms 22.566 ms * 4 loopback0.0003.corx.01.ham.de.net.telefonica.de (::ffff:62.52.192.179) 20.166 ms * 21.472 ms 5 2a02:3001::1b8 (2a02:3001::1b8) 16.652 ms 2a02:3001::1b7 (2a02:3001::1b7) 18.380 ms 2a02:3001::22d (2a02:3001::22d) 22.922 ms 6 2001:4860:1:1::ff1 (2001:4860:1:1::ff1) 18.274 ms * 18.256 ms 7 2001:4860:0:1::8123 (2001:4860:0:1::8123) 17.437 ms 2001:4860:1:1::56a (2001:4860:1:1::56a) 22.339 ms 2001:4860:1:1::ff0 (2001:4860:1:1::ff0) 14.614 ms 8 2001:4860:0:1::8123 (2001:4860:0:1::8123) 19.795 ms 19.598 ms any-in-2001-4860-4802-32--15.1e100.net (2001:4860:4802:32::15) 20.496 ms
Des weiteren gleiches Problem z.B. bei edition.cnn.com . Die ist bei Fastly gehostet. Bei Cloudflare gehosteten Webseiten kann ich das Problem derzeit auch nicht nachstellen.
Hmm, ich habe das gerade nachgeprüft und Stand jetzt (10.10.2024, 08:30) sehe ich bei mir gar “connection reset” mehr - auch bei Seiten, die zuvor nicht funktionierten.
Interessanterweise ist der traceroute zu xkcd.com jetzt auch einige Hops kürzer:
Sollte das Problem also zumindest bei mir gelöst sein? Das wäre jedenfalls eine sehr, sehr gute Nachricht. Na ja, ich werde den Tag aber nicht vor dem Abend loben und später noch mal schauen (bzw. es würde mir sicher im Laufe des Tages durch Fehler auffallen).
Hier ist ein interessantes Paper zum Thema Stabilität von Anycast für TCP Verbindungen: Does Anycast Hang up on You?
Wenn man das so liest, stehen einem die Haare zu Berge. In der Zusammenfassung steht da:
Consistent with wide use of anycast in CDNs, we found that anycast almost always works—98% of vantage points (VPs) see few or no changes. However, we found a few VPs—about 1%—that see frequent route changes and so are anycast unstable.
(Fettdruck von mir)
Mein Interpretation des Papers ist in etwa: für die großen CDNs (sowas wie Cloudflare, Fastly etc). ist Anycast total hip; allerdings erkaufen die sich die tolle Skalierbarkeit ihrers Netzwerks damit, dass potentiell 1% der User unter instabilen Verbindungen leiden. Zu diesen 1% gehören z.B. wir Internet-User im O2-Netz in Berlin.
Wir nörgeln dann bei unserem Provider rum, und der Provider muss dann die Anycast-Probleme debuggen, und sein Route-Balancing anpassen, damit die CDNs wieder gehen. Dabei ist der Provider gar nicht wirklich schuld. TCP Anycast hat, so wie das derzeit ausgerollt wird, einfach keine saubere Stabilitätsgarantie. Solange da keine besseren Technologien existieren, müssen die Provider (und wir User) die Suppe auslöffeln, die uns die CDNs eingebrockt haben.
Früher wurde das load-balancing nur via DNS gemacht (Akamai macht das immer noch so?), da gab es keine derartigen Probleme. Vergleich der Ansätze z.B. hier erläutert.
Andererseits find ich, dass das auch ziemlich armseeliges Monitoring auf Seiten von z.B. Fastly ist: das Auftreten von Anycast Flips könnten die eigentlich in ihrem Netzwerk trivial feststellen, wenn die da nur ein bischen Metadaten zu TCP SYN und RST Paketen aufzeichen und ab und zu analysieren.
tmHmm, ich habe das gerade nachgeprüft und Stand jetzt (10.10.2024, 08:30) sehe ich bei mir gar “connection reset” mehr - auch bei Seiten, die zuvor nicht funktionierten.
Interessanterweise ist der traceroute zu xkcd.com jetzt auch einige Hops kürzer:
Also bei mir nach wie vor das gleiche Problem, bei der gleichen IPv6, die du benutzt:
$ https_proxy= curl --resolve xkcd.com:443:2a04:4e42:600::67 https://xkcd.com > /dev/null % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 curl: (35) OpenSSL SSL_connect: Connection reset by peer in connection to xkcd.com:443
(mit dem normalen traceroute, endet der trace nach dem 6. Host)
Ahh, wir machen das falsch. MTR kann auch TCP-Pakete tracen. Wenn wir die obige IP Adresse tracen, wie TCP Traffic an Port 443 geroutet wird, dann bekommen wir eine instabiles routing (Abweichung ab Host 5). Außerdem sehen wir jetzt die hops 3-4, die das normale ping-basierte MTR nicht auflöst. Man braucht BTW option --report-wide um vollständige IPv6 adressen zu sehen.
Zumindest pages.github.io liegt auch bei fastly (sieht man auch beim mtr)
Ansonsten wäre es vielleicht an der Zeit, auch mal ein issue über den normalen Telefonsupport aufzumachen mit Verweis auf diesen Thread?
Hallo allerseits,
das sind wirklich Einblicke, da bin ich persönlich auch nur noch Ansatzweise in der Lage, die komplett zu verstehen. Muss ich ja aber auch nicht, dafür haben wir ja Leute :-)
Ich habe eure Erkenntnisse noch einmal an passende Stellen angebracht, sobald ich da ein paar meehr Einblicke und Antworten zurück erhalte, melde ich mich auf jeden Fall erneut.
Ich weiß, das ganze ist etwas langwierig, wir bleiben aber dennoch auch weiterhin dran :-)
Gruß,
Lars
Also jetzt aktuell tritt das Problem bei pages.github.com wieder auf:
$ https_proxy= curl -v -6 https://pages.github.com > /dev/null % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0* Trying 2606:50c0:8003::153:443... * Connected to pages.github.com (2606:50c0:8003::153) port 443 (#0) * ALPN, offering h2 * ALPN, offering http/1.1 * successfully set certificate verify locations: * CAfile: /etc/ssl/certs/ca-certificates.crt * CApath: /etc/ssl/certs } [5 bytes data] * TLSv1.3 (OUT), TLS handshake, Client hello (1): } [512 bytes data] * OpenSSL SSL_connect: Connection reset by peer in connection to pages.github.com:443 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 * Closing connection 0 curl: (35) OpenSSL SSL_connect: Connection reset by peer in connection to pages.github.com:443
Ich hab das Problem jetzt mal beim Fastly support unter https://support.fastly.com/hc/en-us über das support-formular geschildert. Bin richtig überrascht, dass das geht, auch wenn man gar keinen Fastly Account hat. Jetzt bin ich gespannt, ob da außer der Ticket-Confirmation Email noch irgendwas sachdienliches zurückkommt.
Irgendwie hoffe ich ja, dass ich irgendwann dieses Jahr IPv6 wieder für mein Heimnetz aktivieren kann.
Aktuell habe ich auch wieder Probleme mit Cloudflare (fastly sowieso):
Symptome: Webseite lädt im Browser nicht bzw. nur unvollständig.
Ich verstehe, dass das Problem nicht einfach zu beheben ist, aber ipv6 ist für mich im täglichen Arbeiten inzwischen unverzichtbar, daher bereite ich gerade die Kündigung bei o2 vor. Es macht einfach keinen Sinn, im Durchschnitt 1-2 Arbeitsstunden pro Woche zu verlieren, weil irgendwelche Prozesse wieder nicht durchlaufen.
Hallo zusammen,
ich hatte ein ähnliches Problem (zufällige “Connection reset by peer”) beim Zugriff auf githubusercontent.com (durch “brew update” per curl).
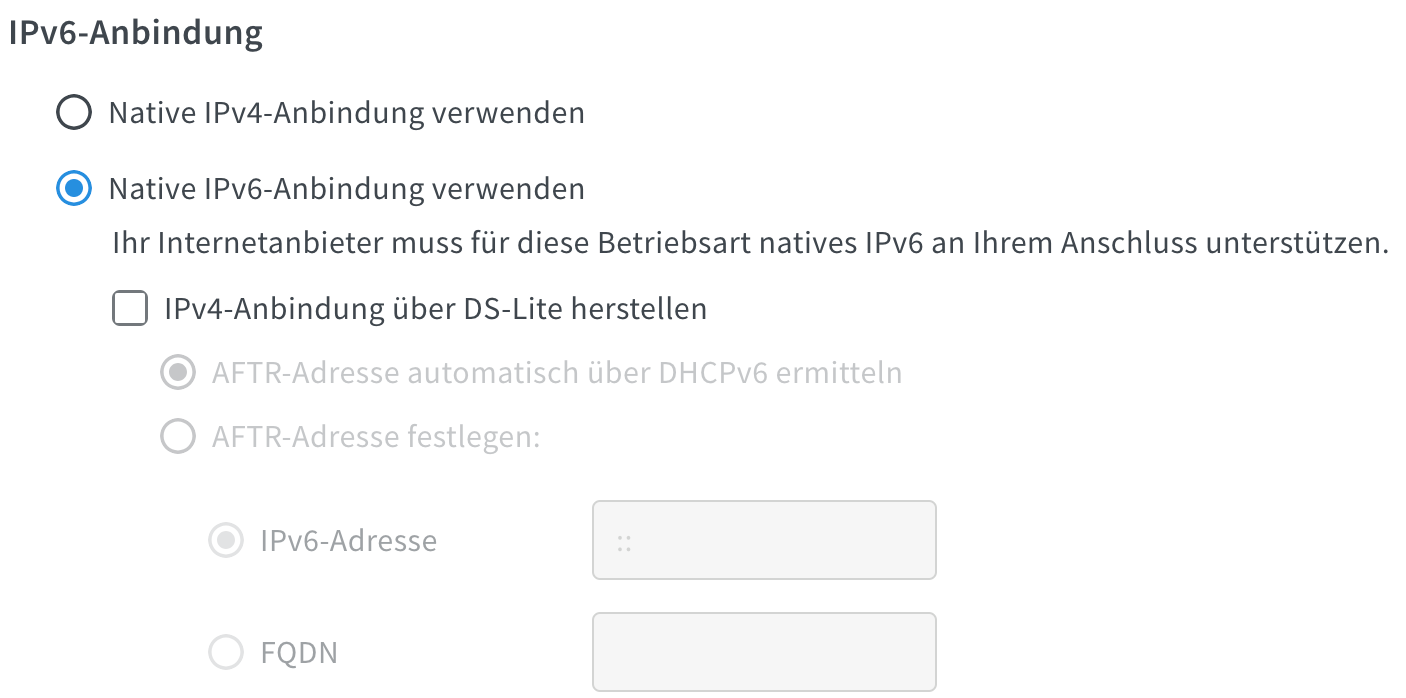
Das Problem scheint nun behoben zu sein nachdem ich meine FritzBox 7490 auf “Native IPv6 Verbindung verwenden” von IPv4 umgestellt habe (Internet → Zugangsdaten → IPv6 Reiter):
Das Problem scheint nun behoben zu sein nachdem ich meine FritzBox 7490 auf “Native IPv6 Verbindung verwenden” von IPv4 umgestellt habe (Internet → Zugangsdaten → IPv6 Reiter)
Hmm es wundert mich eher dass es damit zur Lösung kam. Arbeiten die AVM Geräten vielleicht anders? Wenn ich bei mir DHCP6 nicht über den IPv4 Link laufen lasse, kriege ich auch keine IPv6 Adressen.
Vielleicht gibt es ja eine änderung seitens Infrastrukturbetreiber, letztendlich sind ja auch alle Anleitungen dazu inzwischen einige Jahre alt und mögen dazu auch nicht den aktuellsten Stand wiederspiegeln. Es gibt meines Wissens aber auch keine “einfache/explizite” Dokumentation seitens dem Infrastrukturbetreiber selber.
Meine vermutung ist eher, dass du entweder mit der Einstellung kein IPv6 mehr hast (wenn meine Interpretation korrekt ist und DHCP6 weiterhin “nur” über IPv4 funktioniert), oder es liegt an einem neuen Präfix den du halt durch die Einstellungsänderung erhalten hast, der vom Problem nicht betroffen ist.
Hallo zusammen,
ich hatte ein ähnliches Problem (zufällige “Connection reset by peer”) beim Zugriff auf githubusercontent.com (durch “brew update” per curl).
Das Problem scheint nun behoben zu sein nachdem ich meine FritzBox 7490 auf “Native IPv6 Verbindung verwenden” von IPv4 umgestellt habe (Internet → Zugangsdaten → IPv6 Reiter):
Ein kleines Update: Das Problem scheint dadurch nur kurzfristig behoben zu sein. Nach ca 2-3 Minuten nach der Umstellung tritt’s wieder auf.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
Scanne Datei nach Viren
Tut uns leid, wir prüfen noch den Inhalt dieser Datei, um sicherzustellen, dass sie gefahrlos heruntergeladen werden kann. Bitte versuche es in wenigen Minuten erneut.